Whilst it is possible to configure “log shipping” between different versions of SQL Server, the result can only be used for disaster recovery.
This is because “standby mode” (where the data could be read on GCP) requires the same versions of SQL Server on the primary and secondary servers.
The automatic upgrading of the database objects (from say 2008r2, to say 2017), when brought online could not happen fast enough to support the continuous nature of “standby mode”.
Often when a stored-procedure is executed I want to know the parameters that were input. Which is handy for performance tuning.
There is a mechanism to automatically save input parameters with the cached execution plans, but quite often this does not work well.
On this occasion I embedded the facility right into the procedure as a temporary measure (please, don’t talk to me about triggers brrr).
CREATE PROCEDURE [dbo].[sp_SomeName]
@ID UNIQUEIDENTIFIER = NULL,
@Record VARCHAR(50) = NULL
AS
BEGIN
/* log parameters for performance tuning 1 of 2 */
IF OBJECT_ID('[SomeDatabase].[dbo].[tbl_SomeTable]') IS NULL
SELECT GETDATE() STIME, GETDATE() ETIME, @ID ID, @Record RC
INTO [dbo].[tbl_SomeTable]
ELSE
INSERT INTO [dbo].[tbl_SomeTable]
SELECT GETDATE(), GETDATE(), @ID, @Record
/* log parameters for performance tuning 1 of 2 */
...
Overkill really, but at the end of the procedure I added …
...
/* log parameters for performance tuning 2 of 2 */
UPDATE [dbo].[tbl_SomeTable]
SET ETIME = getdate()
WHERE ETIME = STIME;
/* log parameters for performance tuning 2 of 2 */
END
GO
Note: the real procedure had many more input parameters, and I suspected they are all set to null. Which would explain the poor performance.
This project was to refresh data every night from a production SQL Server table to a cloud-based MySQL Server. (see my previous post on preparation).
On the GCP website
I created a minimal MySQL instance (which I think of as a “Server”) with a single zone and a Standard machine type (being 1vCPU and 3.75 GB of memory).
Storage I set to a 100GB HDD. Then added an Authorised Network comprising an ip-address range covering our production servers along with a friendly name. I disabled auto storage increase, backups, and point-in-time recovery.
I created a database specifically for this project, and a User (with password) restricted to the same ip-address as above.
Finally, because I would be copying data from a MS-SQL table into a MySQL table (which is not 100% compatible), I set flag “sql_mode” to “ANSI”.
On the Production SQL Server
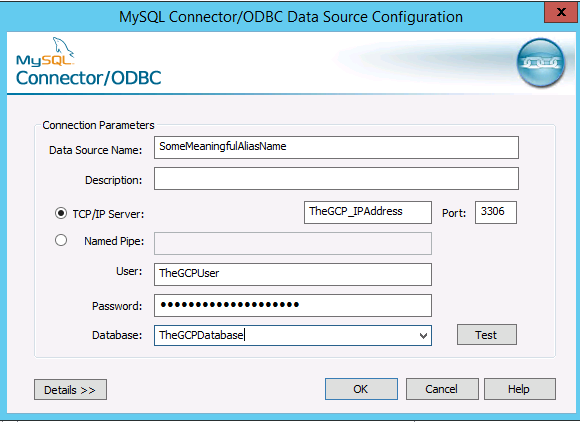
I downloaded the current MySQL 32 bit ODBC driver and configured a new ODBC data source.
Then I created a 2-step SQL Job scheduled to run every night.
Step-1 Collects and saves the data into a purpose made table using a stored-procedure. Replacing the old data.
Step-2 Uploads the table from step-1 into the GCP database using an SSIS package.
To help (with tasks like creating, deleting, viewing and testing tables), I installed the MySQL admin tool “My Workbench” locally. Even so, the SSIS package took a time to perfect. It had to :-
Connect to the source and target servers.
Replace all the target data every time it ran – for robustness.
Refer to reserved column names using double-quotes.
Ensure target data-type and sizes exactly matched the source.