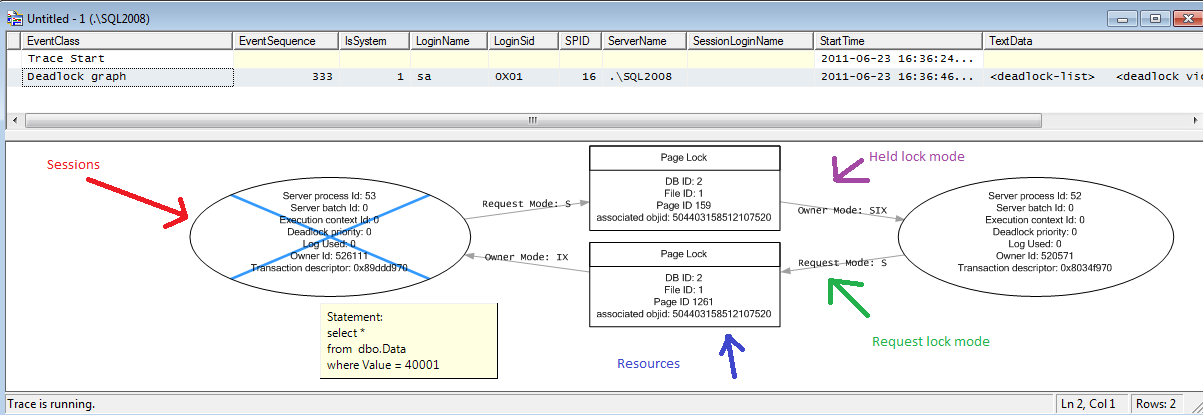
Based on the work of GS, here is my script to create a Job that collects wait stats every 15 minutes.
--CreateJob_DBA_CollectWaitStats.sql
USE [msdb]
GO
IF EXISTS (SELECT job_id FROM msdb.dbo.sysjobs_view WHERE name = N'DBA_CollectWaitStats')
EXEC msdb.dbo.sp_delete_job @job_name=N'DBA_CollectWaitStats', @delete_unused_schedule=1
GO
USE [msdb]
GO
BEGIN TRANSACTION
DECLARE @ReturnCode INT
SELECT @ReturnCode = 0
IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'Database Maintenance' AND category_class=1)
BEGIN
EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'Database Maintenance'
IF (@@ERROR 0 OR @ReturnCode 0) GOTO QuitWithRollback
END
declare
@today varchar(50) = (select convert(varchar, getdate(), 112)),
@nextweek varchar(50) = (select convert(varchar, getdate()+8, 112)),
@dbname varchar(50) = 'master' --<<<<<>>>>>>>>
DECLARE @jobId BINARY(16)
EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'DBA_CollectWaitStats',
@enabled=1,
@notify_level_eventlog=0,
@notify_level_email=0,
@notify_level_netsend=0,
@notify_level_page=0,
@delete_level=0,
@description=N'Collects wait stats for performance tuning.',
@category_name=N'Database Maintenance',
@owner_login_name=N'sa', @job_id = @jobId OUTPUT
IF (@@ERROR 0 OR @ReturnCode 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Create the table',
@step_id=1,
@cmdexec_success_code=0,
@on_success_action=3,
@on_success_step_id=0,
@on_fail_action=3,
@on_fail_step_id=0,
@retry_attempts=0,
@retry_interval=0,
@os_run_priority=0, @subsystem=N'TSQL',
@command=N'create table [dbo].[WaitStats]
(
WaitType nvarchar(60) not null,
NumberOfWaits bigint not null,
SignalWaitTime bigint not null,
ResourceWaitTime bigint not null,
SampleTime datetime not null
)',
@database_name=@dbname,
@flags=0
IF (@@ERROR 0 OR @ReturnCode 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Collect current waits',
@step_id=2,
@cmdexec_success_code=0,
@on_success_action=1,
@on_success_step_id=0,
@on_fail_action=2,
@on_fail_step_id=0,
@retry_attempts=0,
@retry_interval=0,
@os_run_priority=0, @subsystem=N'TSQL',
@command=N'INSERT INTO [dbo].[WaitStats]
SELECT wait_type as WaitType,
waiting_tasks_count AS NumberOfWaits,
signal_wait_time_ms AS SignalWaitTime,
wait_time_ms - signal_wait_time_ms AS ResourceWaitTime,
GETDATE() AS SampleTime
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (
N''BROKER_EVENTHANDLER'', N''BROKER_RECEIVE_WAITFOR'',
N''BROKER_TASK_STOP'', N''BROKER_TO_FLUSH'',
N''BROKER_TRANSMITTER'', N''CHECKPOINT_QUEUE'',
N''CHKPT'', N''CLR_AUTO_EVENT'',
N''CLR_MANUAL_EVENT'', N''CLR_SEMAPHORE'',
N''DBMIRROR_DBM_EVENT'', N''DBMIRROR_EVENTS_QUEUE'',
N''DBMIRROR_WORKER_QUEUE'', N''DBMIRRORING_CMD'',
N''DIRTY_PAGE_POLL'', N''DISPATCHER_QUEUE_SEMAPHORE'',
N''EXECSYNC'', N''FSAGENT'',
N''FT_IFTS_SCHEDULER_IDLE_WAIT'', N''FT_IFTSHC_MUTEX'',
N''HADR_CLUSAPI_CALL'', N''HADR_FILESTREAM_IOMGR_IOCOMPLETION'',
N''HADR_LOGCAPTURE_WAIT'', N''HADR_NOTIFICATION_DEQUEUE'',
N''HADR_TIMER_TASK'', N''HADR_WORK_QUEUE'',
N''KSOURCE_WAKEUP'', N''LAZYWRITER_SLEEP'',
N''LOGMGR_QUEUE'', N''MEMORY_ALLOCATION_EXT'',
N''ONDEMAND_TASK_QUEUE'',
N''PREEMPTIVE_XE_GETTARGETSTATE'',
N''PWAIT_ALL_COMPONENTS_INITIALIZED'',
N''PWAIT_DIRECTLOGCONSUMER_GETNEXT'',
N''QDS_PERSIST_TASK_MAIN_LOOP_SLEEP'', N''QDS_ASYNC_QUEUE'',
N''QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'',
N''QDS_SHUTDOWN_QUEUE'',
N''REQUEST_FOR_DEADLOCK_SEARCH'', N''RESOURCE_QUEUE'',
N''SERVER_IDLE_CHECK'', N''SLEEP_BPOOL_FLUSH'',
N''SLEEP_DBSTARTUP'', N''SLEEP_DCOMSTARTUP'',
N''SLEEP_MASTERDBREADY'', N''SLEEP_MASTERMDREADY'',
N''SLEEP_MASTERUPGRADED'', N''SLEEP_MSDBSTARTUP'',
N''SLEEP_SYSTEMTASK'', N''SLEEP_TASK'',
N''SLEEP_TEMPDBSTARTUP'', N''SNI_HTTP_ACCEPT'',
N''SP_SERVER_DIAGNOSTICS_SLEEP'', N''SQLTRACE_BUFFER_FLUSH'',
N''SQLTRACE_INCREMENTAL_FLUSH_SLEEP'',
N''SQLTRACE_WAIT_ENTRIES'', N''WAIT_FOR_RESULTS'',
N''WAITFOR'', N''WAITFOR_TASKSHUTDOWN'',
N''WAIT_XTP_RECOVERY'',
N''WAIT_XTP_HOST_WAIT'', N''WAIT_XTP_OFFLINE_CKPT_NEW_LOG'',
N''WAIT_XTP_CKPT_CLOSE'', N''XE_DISPATCHER_JOIN'',
N''XE_DISPATCHER_WAIT'', N''XE_TIMER_EVENT'')
AND [waiting_tasks_count] > 0
',
@database_name=@dbname,
@flags=0
IF (@@ERROR 0 OR @ReturnCode 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1
IF (@@ERROR 0 OR @ReturnCode 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Every 15 mins for a week',
@enabled=1,
@freq_type=4,
@freq_interval=1,
@freq_subday_type=4,
@freq_subday_interval=15,
@freq_relative_interval=0,
@freq_recurrence_factor=0,
@active_start_date=@today,
@active_end_date=@nextweek,
@active_start_time=100,
@active_end_time=235959,
@schedule_uid=N'5b0842fe-8f80-44e9-8a09-aac6ce5c2b2e'
IF (@@ERROR 0 OR @ReturnCode 0) GOTO QuitWithRollback
EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)'
IF (@@ERROR 0 OR @ReturnCode 0) GOTO QuitWithRollback
COMMIT TRANSACTION
GOTO EndSave
QuitWithRollback:
IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION
EndSave:
GO